Найти самое популярное слово в тексте
Если у вас есть какой-то текст и вам надо разбить его на слова. То есть несколько способов это сделать.
Первый вариант
Мы его уже использовали, через функцию split. Он не универсальный, но вполне рабочий для простого текста. Где, например, все слова просто отделены друг от друга пробелами. Например
text = "В лесу родилась елочка"
words = text.split(" ")
print(words[1]) # выведет лесу
но этот способ начинает плохо работать, если в тексте есть какие-нибудь знаки препинания. Например
text = "Там царь Кащей над златом чахнет; там русский дух… там Русью пахнет!"
words = text.split(" ")
print(words)

то есть при таком разбиении у нас слова вместе со знаками препинания получаются.
поэтому
Второй вариант
Разбиение с помощью регулярных выражений. Это не много хитрый вариант, выглядит он так
import re
text = "Там царь Кащей над златом чахнет; там русский дух… там Русью пахнет!"
words = re.split("\W+", text)
print(words)
получим такое:

уже лучше, но есть пустые строки, надо их убрать
import re
text = "Там царь Кащей над златом чахнет; там русский дух… там Русью пахнет!"
words = re.split("\W+", text)
words = [i for i in words if i] # убираем пустые строки
print(words)
пробуем
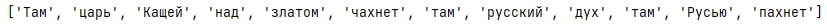
Рекомендация к заданию
Если будете искать самое длинное слово, то скорее всего вы решите фиксировать информацию об этом в словарик. Ну типа ключ – это слово, а значение — это сколько раз слово встречается в тексте.
И в конце концов у вас встанет задача, найти ключ с наибольшем значением. Поиск наибольшего ключа осуществляется примерно так же как поиск наибольшего элемента.
То есть, сначала считаем, что ключ с наибольшем значением – это первый ключ. А получить значением первого ключа можно так
first_key = list(some_dict)[0]
затем вам надо обойти все ключи словарика и проверять у кого значение больше, типа
for key in some_dict:
if some_dict[key] > some_dict[first_key]:
print(f"значение ключа {key} больше чем значение ключа {first_key}"