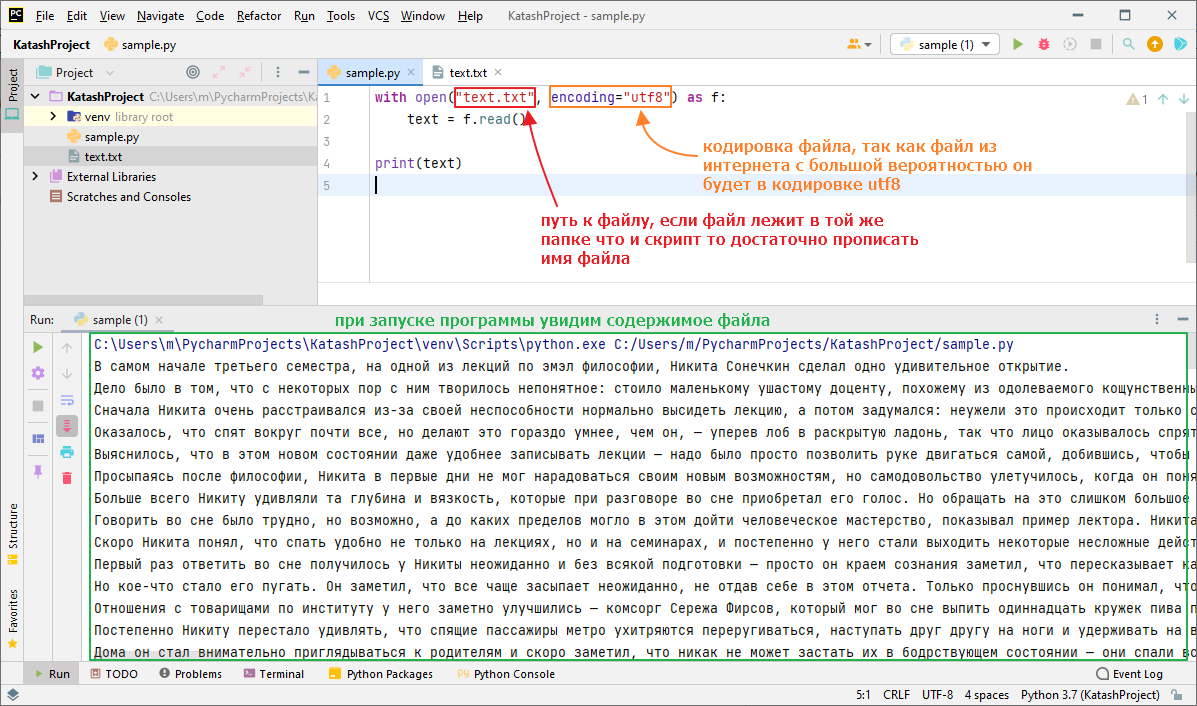
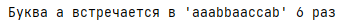Провести частотный анализ текста text.txt. Найти процентную долю каждой буквы от общего количества букв в тексте.
2
Текстовый файл text2.txt состоит из заглавных латинских букв (A..Z). Текст разбит на строки различной длины. Определите количество строк, в которых буква S встречается столько же раз, сколько и буква X.
3
В текстовом файле k8-91.txt находится цепочка из символов, в которую могут входить заглавные буквы латинского алфавита A…Z и десятичные цифры. Найдите длину самой длинной подцепочки, состоящей из одинаковых символов. Если в файле несколько подходящих цепочек одинаковой длины, нужно взять первую из них.
4
В текстовом файле 112_k7a-4.txt находится цепочка из символов латинского алфавита A, B, C, D, E, F. Найдите длину самой длинной подцепочки, не содержащей символа указаного пользователем.